
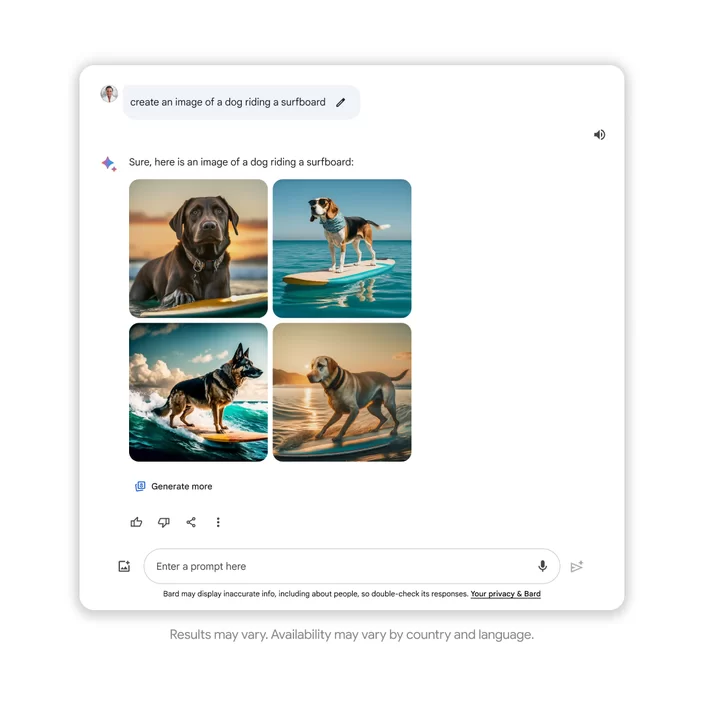
O Google anunciou, nesta quinta-feira (1º), que o Google Bard ganhou o recurso de gerar imagens fotorrealistas a partir de descrições de texto. A novidade faz com que a ferramenta de inteligência artificial (IA) generativa fique parecida com o Dall-E e Midjourney.
Neste lançamento, a nova funcionalidade do Bard cria fotos somente a partir de descrições em inglês. Ou seja, a pessoa pode digitar “dog riding a surfboard”, ou “cachorro surfando em uma prancha”, e ela receberá quatro opções de desenhos gerados por inteligência artificial.
De acordo com a gigante de Mountain View, todas as criações do sistema de IA terão um marca d’água digitalmente identificável nos pixels. O objetivo é ajudar com que as pessoas consigam diferenciar imagens originais das que foram geradas por IA.
A nova habilidade do Bard é resultado da tecnologia Imagen 2, que realiza a integração de processamento de texto para imagem.
Gemini Pro e melhorias na Busca
Além da possibilidade de gerar imagens a partir de texto no Bard, o sistema do Google ganhou mais melhorias hoje. No final do ano passado, a plataforma foi integrada ao Gemini Pro, um modelo de linguagem grandes multimodais.
Na época, a funcionalidade melhorou a compreensão, raciocínio, resumo e codificação da versão em inglês do Bard. Agora, o modelo está disponível em todos os idiomas, incluindo o português.
A outra função apresentada pelo Google foi a “Dupla verificação”, que corrobora as respostas fornecidas pelo Bard. Ela será disponibilizada em 40 idiomas, incluindo em português, e permite que o usuário realize buscas no Google a partir de respostas dadas pelo Bard.
A ideia é aprofundar as informações e ter acesso a diferentes fontes que validem os dados. Também será possível clicar em frases destacadas para obter informações que apoiem ou contradigam o que foi respondido.



{kind=link}