

{kind=link}
Pesquisadores da Microsoft anunciaram na última semana o VALL-E, um modelo de Inteligência Artificial capaz de converter texto em fala, enquanto simula a voz de outra pessoa. A IA é capaz de simular vozes com amostras de áudio de apenas três segundos. Após aprender a voz, o VALL-E é capaz de sintetizar áudio e reproduzir a voz do locutor enquanto lê textos.
O interessante é que o VALL-E não imita a voz com base em textos pré-determinados, ele consegue simular a entonação e reproduzir as emoções enquanto lê frases completamente diferentes da reproduzida pelo locutor. De acordo com os pesquisadores da Microsoft, o VALL-E pode ser usado para aplicativos de conversão de texto em fala de alta qualidade, edição de fala em que uma gravação de uma pessoa pode ser editada e alterada de uma transcrição de texto (fazendo-a dizer algo que originalmente não disse), e criação de conteúdo de áudio quando combinado com outros modelos generativos de IA.
Como o VALL-E funciona
O VALL-E é um “modelo de linguagem de codec neural” e é baseado na tecnologia EnCodec, anunciado pela Meta em outubro de 2022. Para ser capaz de sintetizar vozes, a IA gera códigos de codec de áudio a partir de prompts da fala do locutor. Ao invés de apenas sintetizar a onda do áudio, o VALL-E é capaz de “analisar como a pessoa fala” e dividir a informação em pequenos tokens.
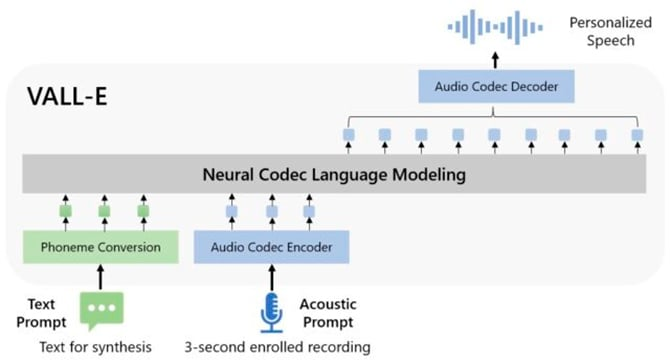
Para sintetizar e reproduzir diferentes textos enquanto simula a voz do locutor, o VALL-E: “gera os tokens acústicos correspondentes condicionados aos tokens acústicos da gravação registrada de 3 segundos. Finalmente, os tokens acústicos gerados são usados para sintetizar a forma de onda final com o decodificador codec neural correspondente”, comentou a Microsoft na página oficial do VALL-E.
VALL-E simula tom de voz e emoções
No site oficial do VALL-E, a Microsoft mostra diversos exemplos de como a IA funciona. Dentre as opções de reprodução de áudio podemos ver o “Speaker Prompt”, que é o áudio de três segundos fornecidos ao VALL-E. O “Ground Truth” é a mesma frase que será reproduzida pelo VALL-E, dita pelo locutor a fins de comparação (áudio controle), e a amostra VALL-E é o texto reproduzido pela inteligência artificial.
É importante ressaltar que o VALL-E reproduz o texto com base nas informações obtidas da frase “Speaker Prompt”, já o “Ground Truth” é utilizado como comparação. Ou seja, a IA é capaz de reproduzir vozes e ler textos com base em áudios com informações completamente diferentes do que ela está lendo.
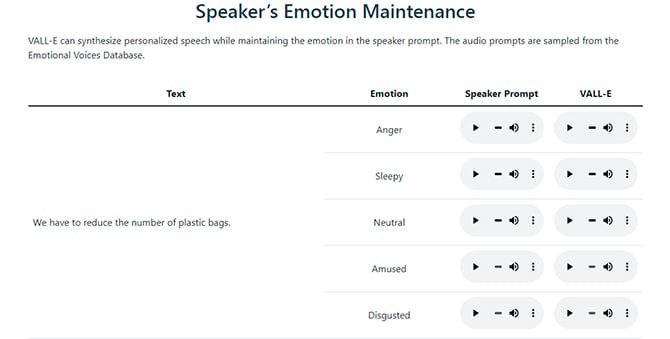
O mais interessante é que a IA também é capaz de reproduzir emoções. No print acima, extraído do site da VALL-E, podemos ver como o VALL-E reproduz diferentes emoções, como raiva, enquanto diz a frase “Nós temos que reduzir o número de sacos plásticos”. O interessante, é que as informações são extraídas de áudios com frases distintas. Enquanto um locutor diz de forma irritada “O rosto dela estava pressionado no peito dele”, a IA reproduz a voz do locutor, também irritada, e lê a frase dos sacos plásticos.
O resultado final é impressionante, e chega a ser surreal a forma como a inteligência artificial consegue reproduzir com facilidade o tom e emoção das vozes do locutor. Apesar de nem todos os resultados serem extremamente parecidos, a IA mostra que no futuro será muito fácil reproduzir a voz de alguém para simular qualquer frase, algo que pode ser assustador.
Por Luiz Schmidt